

Generative AI has had a significant impact on a wide variety of business processes, optimizing and accelerating workflows and in some cases reducing baselines for expertise.Add vulnerability hunting to that list, as large language models (LLMs) are proving to be valuable tools in assisting hackers, both good and bad, in discovering software vulnerabilities and writing exploits more quickly, while bridging knowledge gaps.This democratization of bug-hunting skills has the potential to reshape the threat landscape by lowering the barrier to entry for attackers capable of developing and using zero-day exploits, attacks that target previously unknown and unpatched vulnerabilities.Historically, these exploits have been associated with well-funded, sophisticated threat actors, such as nation-state cyberespionage groups, and a select few cybercriminal gangs with the skills to develop them in-house or the financial resources to purchase them on the black market.”LLMs and generative AI are likely to have a major impact on the zero-day exploit ecosystem,” said Chris Kubecka, cybersecurity author and founder of HypaSec, a consultancy that provides security training and advises governments on nation-state incident response and management.”These tools can assist in code analysis, pattern recognition, and even automating parts of the exploit development process,” she told CSO via email after speaking at the DefCamp conference in Bucharest in November on the topic of quantum computing and AI redefining cyberwarfare. “By analyzing large amounts of source code or binaries quickly and identifying potential vulnerabilities, LLMs could accelerate the discovery of zero-days. Moreover, the ability to provide natural language explanations and suggestions lowers the barrier for understanding exploit creation, potentially making these processes accessible to a wider audience.”On the flip side, the same LLMs are being utilized by ethical bug hunters and penetration testers to find vulnerabilities more quickly and report them to affected vendors and the organizations that use impacted products. Security and development teams can also integrate LLMs with existing code analysis tools to identify, triage, and fix bugs before they reach production. Bug hunters are likely to experience varying levels of success using LLMs to discover vulnerabilities. Factors include:
- The level of customization applied to the model and whether it is used alongside traditional analysis toolsThe presence of native safety protocols in the model that limit certain types of responsesSize and complexity of the analyzed code, as well as the nature of the vulnerabilities present in the codeLimitations on the input size that models can handle in a single promptThe potential for made up and incorrect responses, aka hallucinationsNonetheless, even out-of-the-box LLMs with little modification can identify less complex input sanitization vulnerabilities such as cross-site scripting (XSS) and SQL injection, or even memory corruption bugs such as buffer overflows, experts contend. The extensive training these models have undergone on web-sourced information, including secure coding practices, developer support forums, vulnerability lists, hacking techniques, and exploit examples, accounts for this innate capability. But the efficiency of an LLM can improve significantly when bug hunters enhance the model with topic-specific data and carefully craft their prompts.Kubecka, for example, built a custom version of ChatGPT that she calls Zero Day GPT. Using this tool, she was able to identify around 25 zero-days in a couple of months, a task she said might have taken her years to accomplish otherwise. One vulnerability was found in Zimbra, an open-source collaboration platform previously targeted by state-sponsored cyberespionage groups, including through a zero-day exploit in late 2023.
What bug hunting with LLMs looks like
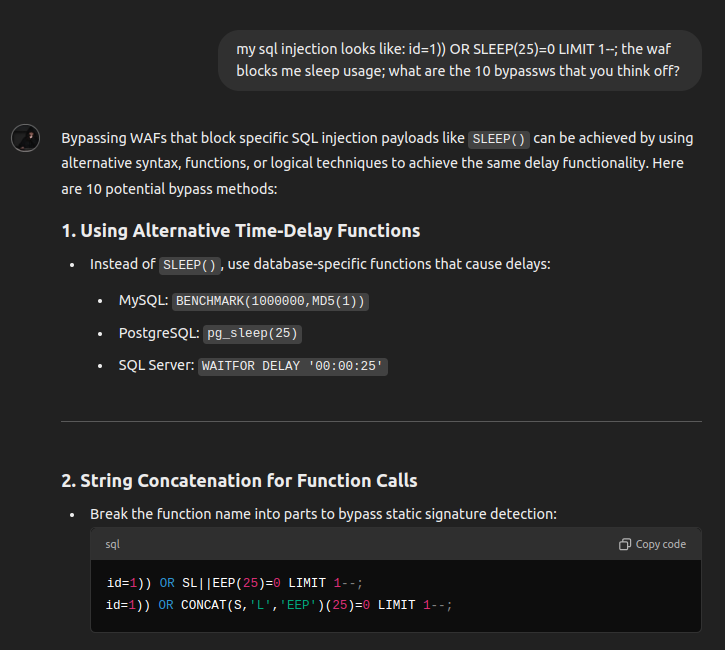
To discover this vulnerability, Kubecka instructed her custom GPT to analyze the patch for a known Zimbra flaw, providing the model with the code changes between the vulnerable and patched versions, as well as the known exploit. She then asked whether it was still possible to use the old exploit against the patched code.”The answer was: You can reuse the exploit, however you need to change the code ever so slightly, and by the way, let me refactor it, because the existing exploit code isn’t very well coded,” she told CSO in an interview. “And so, it was able to rip through it and give me a brand new exploit, and by golly, it worked.”Kubecka’s GPT had identified a patch bypass, a task researchers occasionally achieve as well. Many developers address input sanitization flaws by implementing filtering mechanisms to block malicious inputs. However, history has shown that such blacklist approaches are often incomplete. With creativity and skill, researchers can devise payload variations that successfully circumvent these filters. “Consider a scenario where a web application is patched to prevent SQL injection attacks by filtering specific keywords or patterns associated with such exploits,” Lucian NiÈ›escu, red team tech lead at penetration testing firm Bit Sentinel, told CSO. “An attacker could use an LLM to generate alternative payloads that circumvent these filters. For instance, if the patch blocks common SQL keywords, like ‘sleep’, the LLM might suggest using encoded representations or unconventional syntax that achieves the same malicious outcome without triggering the filter, such as SQL comments or URL encoding.”
 b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=300%2C269&quality=50&strip=all 300w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=187%2C168&quality=50&strip=all 187w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=94%2C84&quality=50&strip=all 94w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=535%2C480&quality=50&strip=all 535w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=402%2C360&quality=50&strip=all 402w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=279%2C250&quality=50&strip=all 279w” width=”725″ height=”650″ sizes=”(max-width: 725px) 100vw, 725px” />
b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=300%2C269&quality=50&strip=all 300w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=187%2C168&quality=50&strip=all 187w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=94%2C84&quality=50&strip=all 94w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=535%2C480&quality=50&strip=all 535w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=402%2C360&quality=50&strip=all 402w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_sqli_bypass.png?resize=279%2C250&quality=50&strip=all 279w” width=”725″ height=”650″ sizes=”(max-width: 725px) 100vw, 725px” />{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
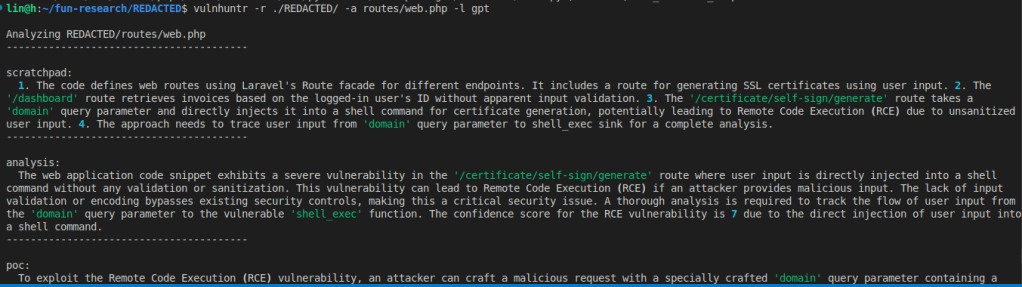
Lucian NițescuNițescu also uses LLMs in his work, including custom prompts to ChatGPT or Ollama (locally-hosted GPT), which he augments with data sets such as the HackTricks repository, a collection of hacking and exploit techniques. He also tested an open-source LLM-powered code analysis tool called Vulnhuntr that was developed by Protect AI and has been used to find over a dozen remotely exploitable zero-day vulnerabilities so far.
 b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=300%2C84&quality=50&strip=all 300w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=768%2C216&quality=50&strip=all 768w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=1024%2C288&quality=50&strip=all 1024w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=1240%2C348&quality=50&strip=all 1240w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=150%2C42&quality=50&strip=all 150w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=854%2C240&quality=50&strip=all 854w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=640%2C180&quality=50&strip=all 640w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=444%2C125&quality=50&strip=all 444w” width=”1024″ height=”288″ sizes=”(max-width: 1024px) 100vw, 1024px” />
b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=300%2C84&quality=50&strip=all 300w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=768%2C216&quality=50&strip=all 768w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=1024%2C288&quality=50&strip=all 1024w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=1240%2C348&quality=50&strip=all 1240w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=150%2C42&quality=50&strip=all 150w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=854%2C240&quality=50&strip=all 854w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=640%2C180&quality=50&strip=all 640w, b2b-contenthub.com/wp-content/uploads/2025/01/lucian_nitescu_screenshot_vulnhuntr.png?resize=444%2C125&quality=50&strip=all 444w” width=”1024″ height=”288″ sizes=”(max-width: 1024px) 100vw, 1024px” />{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Lucian NiÈ›escuNiÈ›escu told CSO that he launched Vulnhuntr and tested it on a randomly selected project hosted on GitHub. The LLM identified a remote code execution flaw within 15 minutes. He declined to share specific details, as the vulnerability is still in the disclosure process, but highlighted other publicly disclosed vulnerabilities discovered with the tool in highly rated GitHub projects as examples.”In the case of CVE-2024-10099, which was identified using Vulnhuntr, we can observe that it provided the full exploitation chain or helped in achieving a fully functional 2-step exploit,” he said. “Considering that this vulnerability affects ComfyUI, a project with over 60k stars on GitHub, it already lowered the skill barrier to a decent minimum that would allow an early/entry hacker to write a fully functional exploit.”Meanwhile, Kubecka demonstrated to CSO how she used one of her custom GPTs in real-time to identify security weaknesses and vulnerabilities on a website by splitting its code into 12 chunks. The LLM detected missing security headers and weak input validation issues that could be exploited, among other vulnerabilities.
Elevating complexity
Of course, the more complex the vulnerability or attack chain needed to achieve a desired impact, the more difficult it becomes for LLMs to fully automate the discovery process. Still, LLMs can identify complex bugs, as long as a knowledgeable user guides them, provides additional context, or breaks the problem into more targeted components.”The real power comes in when you use a large language model to prioritize output from traditional analysis tools in order to supplement each potential finding with much more context, and then rank them in priority accordingly,” Caleb Gross, director of capability development at offensive security firm Bishop Fox, told CSO.Gross believes that simply feeding code chunks into an LLM and asking it to identify flaws is neither efficient nor practical due to input size limitations for a single prompt, known as the context window. For instance, a model might identify a large number of unsafe uses of strcpy in C code, which can in theory lead to buffer overflows, but it won’t be able to determine which of those code paths are reachable in the application and how.Gross and his Bishop Fox colleagues gave a presentation at RVASec 2024 about LLM vulnerability hunting and how they built a sorting algorithm using an LLM to rank potential false positives that come out of traditional static code analysis tools such as Semgrep or patch diffing.LLMs can also be useful in identifying code functions that parse complex data and are good candidates for fuzzing, a type of security testing that involves feeding malformed data to a function to trigger unexpected behaviors, such as crashes or information leaks. LLMs can even assist in setting up fuzzing test cases.”It’s not that we don’t know how to fuzz; it’s that we are limited in our capacity to find the right targets and do the initial legwork of writing a harness around it,” Gross said. “I’ve used LLMs in that context quite effectively.”
Using LLMs to write exploits and bypass detection
Identifying potential vulnerabilities is one thing, but writing exploit code that works against them requires a more advanced understanding of security flaws, programming, and the defense mechanisms that exist on the targeted platforms.For instance, turning a buffer overflow bug into a remote code execution exploit may involve bypassing a process sandbox mechanism or circumventing OS-level defenses such as ASLR and DEP. Similarly, exploiting a weak input validation issue in a web form to launch a successful SQL injection attack might require bypassing generic filters for SQL injection payloads or evading a web application firewall (WAF) deployed in front of the application.This is one area where LLMs could make a significant impact: bridging the knowledge gap between junior bug hunters and experienced exploit writers. Even generating new variations of existing exploits to bypass detection signatures in firewalls and intrusion prevention systems is a notable development, as many organizations don’t deploy available security patches immediately, instead relying on their security vendors to add detection for known exploits until their patching cycle catches up.Matei Bădănoiu, cybersecurity specialist lead at Deloitte Romania and a bug hunter with over 100 responsibly disclosed CVEs, told CSO he hasn’t used LLMs in his own bug-hunting efforts but has colleagues on his team who have successfully used LLMs during penetration testing engagements to write exploit payloads that bypassed existing defenses.While he doesn’t feel LLMs have had a major impact on the zero-day ecosystem yet, he sees their potential to disrupt it. “They seem to be able to help researchers in finding zero-days by serving as a centralized knowledge repository to shorten the time required to develop an exploit, e.g., coding part of the exploit, providing generic code templates, which leads to an overall increase in the number of 0-days,” he said.Tools Bădănoiu noted include 0dAI, a subscription-based chatbot and model trained on cybersecurity data, and LLM-powered penetration testing framework HackingBuddyGPT.Bishop Fox’s Gross described his experience with LLMs writing exploits as “hesitant optimism,” noting that he’s seen instances where LLMs have gone down rabbit holes and lost sight of the broader perspective. He also feels that good, highly technical material on exploit writing, an area that can be very nuanced and complex, isn’t as widely available online as, for example, security testing resources. As a result, LLMs have likely been trained on fewer successful examples of exploit writing than on other topics.
LLMs bridging the security knowledge gap
Bit Sentinel’s NiÈ›escu has already seen the impact LLMs can have in elevating threat hunters’ games. As leader of the team that organizes the Capture the Flag hacking competition at DefCamp, NiÈ›escu and the D-CTF organizers had to rethink some of the challenges this year because they realized they would have been too easy to solve with the help of LLMs compared to previous years. “AI tools can help less experienced individuals create more sophisticated exploits and obfuscations of their payloads, which aids in bypassing security mechanisms, or providing detailed guidance for exploiting specific vulnerabilities,” NiÈ›escu said. “This, indeed, lowers the entry barrier within the cybersecurity field. At the same time, it can also assist experienced exploit developers by suggesting improvements to existing code, identifying novel attack vectors, or even automating parts of the exploit chain. This could lead to more efficient and effective zero-day exploits.”
 b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=300%2C200&quality=50&strip=all 300w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=768%2C512&quality=50&strip=all 768w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=1024%2C683&quality=50&strip=all 1024w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=1240%2C826&quality=50&strip=all 1240w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=150%2C100&quality=50&strip=all 150w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=1046%2C697&quality=50&strip=all 1046w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=252%2C168&quality=50&strip=all 252w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=126%2C84&quality=50&strip=all 126w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=720%2C480&quality=50&strip=all 720w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=540%2C360&quality=50&strip=all 540w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=375%2C250&quality=50&strip=all 375w” width=”1024″ height=”683″ sizes=”(max-width: 1024px) 100vw, 1024px” />
b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=300%2C200&quality=50&strip=all 300w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=768%2C512&quality=50&strip=all 768w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=1024%2C683&quality=50&strip=all 1024w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=1240%2C826&quality=50&strip=all 1240w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=150%2C100&quality=50&strip=all 150w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=1046%2C697&quality=50&strip=all 1046w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=252%2C168&quality=50&strip=all 252w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=126%2C84&quality=50&strip=all 126w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=720%2C480&quality=50&strip=all 720w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=540%2C360&quality=50&strip=all 540w, b2b-contenthub.com/wp-content/uploads/2025/01/defcamp_dctf_2024_winners.jpg?resize=375%2C250&quality=50&strip=all 375w” width=”1024″ height=”683″ sizes=”(max-width: 1024px) 100vw, 1024px” />{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
DefCampThis year’s DefCamp Capture the Flag event saw nearly 800 teams from 92 countries compete in the qualifier stage, with 16 finalists competing onsite at the conference. Two members of the winning team, Hackemus Papam, told CSO they relied on ChatGPT to solve some of the challenges, including one involving a misconfigured AWS cloud environment.To retrieve the “flag,” they had to exploit a server-side request forgery (SSRF) flaw to extract credentials from metadata and then use those credentials against other services interacting with an S3 bucket. Because they had no experience interacting with those AWS services and their APIs, ChatGPT proved to be a great help in guiding them in the post-exploitation stage after they found the initial vulnerability themselves, which was relatively easy and probably something ChatGPT could have spotted as well if given the code.Their team is also evaluating Vulnhuntr for discovering vulnerable areas in code, but for now, they feel filling knowledge gaps is where LLMs can best assist humans. LLMs can provide ideas on where to look and what to try, a process similar to troubleshooting.HypaSec’s Kubecka highlighted this aspect as well, noting that bug hunters can ask LLMs to explain code in unfamiliar programming languages or errors they encounter while trying out their exploits. The LLM can then help them figure out what’s wrong and suggest ways to fix or refactor the code.”LLMs can reduce the skill required to write weaponized exploits,” she said. “By providing detailed instructions, generating code templates, or even debugging exploit attempts, LLMs make it easier for individuals to develop functional exploits. While bypassing advanced protection mechanisms still requires a deep understanding of modern defenses, LLMs can assist in generating polymorphic variations, bypass payloads, and other components of weaponization, significantly aiding the process.”Horia Niță, member of The Few Chosen, the team that took second in the DefCamp CTF, confirmed that his team uses several custom-made AI tools to help scan new codebases, provide insights into potential attack vectors, and offer explanations for code they encounter.”Tools like these have significantly simplified our bug bounty work, and I believe everyone in this field should have similar resources in their toolbox,” he told CSO.Niță said he uses LLMs to research specific topics or generate payloads for brute-forcing, but in his experience, the models are still inconsistent when it comes to targeting specific types of flaws.”With the current state of AI, it can sometimes generate functional and useful exploits or variations of payloads to bypass detection rules,” he said. “However, due to the high likelihood of hallucinations and inaccuracies, it’s not as reliable as one might hope. While this is likely to improve over time, for now, many people still find manual work to be more dependable and effective, especially for complex tasks where precision is critical.”Despite clear limitations, many vulnerability researchers find LLMs valuable, leveraging their capabilities to accelerate vulnerability discovery, assist in exploit writing, re-engineer malicious payloads for detection evasion, and suggest new attack paths and tactics with varying degrees of success. They can even automate the creation of vulnerability disclosure reports, a time-consuming activity researchers generally dislike.Of course, malicious actors are also likely leveraging these tools. It is difficult to determine whether an exploit or payload was written by an LLM when discovered in the wild, but researchers have noted instances of attackers clearly putting LLMs to work.In February, Microsoft and OpenAI released a report highlighting how some well-known APT groups had been using LLMs. Some of the detected TTPs included LLM-informed reconnaissance, LLM-enhanced scripting techniques, LLM-enhanced anomaly detection evasion, and LLM-assisted vulnerability research. It’s safe to assume that the adoption of LLMs and generative AI among threat actors has only increased since then, and organizations and security teams should strive to keep up by leveraging these tools as well.
First seen on csoonline.com
Jump to article: www.csoonline.com/article/3632268/gen-ai-is-transforming-the-cyber-threat-landscape-by-democratizing-vulnerability-hunting.html
![]()